

简介
MongoDB是一个开源、高性能、无模式(不像列级)的文档型数据库,当初的设计就是用于简化开发和方便扩展,是NoSQL数据库产品中的一种,是最像关系型数据库(MySQL)的非关系型数据库。
它支持的数据结构非常松散,是一种类似于 JSON 的格式叫 BSON,所以它既可以存储比较复杂的数据类型,又相当的灵活。
MongoDB中的记录是一个文档,它是一个由字段和值对(field:value)组成的数据结构。MongoDB文档类似于JSON对象,即一个文档认为就是一个对象。字段的数据类型是字符型,它的值除了使用基本的一些类型外,还可以包括其他文档、普通数组和文档数组。
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接 MongoDB不支持 | |
| 嵌入文档 | MongoDB通过嵌入式文档来替代多表连接 (查询效率要比表连接要高) |
|
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
数据模型
MongoDB的最小存储单位就是文档(document)对象。文档(document)对象对应于关系型数据库的行。数据在MongoDB中以 BSON(Binary-JSON)文档的格式存储在磁盘上。
BSON(Binary Serialized Document Format)是一种类json的一种二进制形式的存储格式,简称Binary JSON。BSON和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。
【选读/点击查看】BSON简介
BSON( Binary Serialized Document Format) 是一种二进制形式的存储格式,采用了类似于 C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的特点,可以有效描述非结构化数据和结构化数据。
BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date(时间)和BinData(二进制数据)类型。
BSON可以做为网络数据交换的一种存储形式,这个有点类似于Google的Protocol Buffer,但是BSON是一种schema-less的存储形式,它的优点是灵活性高,但它的缺点是空间利用率不是很理想。
BSON有三个特点:轻量性、可遍历性、高效性。
BSON类型描述:
| 类型 | 编号 | 别名 | 注释 |
|---|---|---|---|
| Double | 1 | “double” | |
| String | 2 | “string” | |
| Object | 3 | “object” | |
| Array | 4 | “array” | |
| Binary Data | 5 | “binData” | |
| Deprecated(已废弃) | |||
| objectId | 7 | “objectId” | |
| Boolean | 8 | “bool” | |
| Date | 9 | “date” | |
| Null | 10 | “null” | |
| Regular Expression | 11 | “regex” | |
| Deprecated(已废弃) | |||
| JavaScript | 13 | “javascript” | |
| Deprecated(已废弃) | |||
| Deprecated in MongoDB 4.4 | |||
| 32-bit integer | 16 | “int” | |
| Timestamp | 17 | “timestamp” | |
| 64-bit integer | 18 | “long” | |
| Decimal128 | 19 | “decimal” | New in version 3.4 |
| Min Key | -1 | “minKey” | |
| Max Key | 127 | “maxKey” |
BSON主要会实现以下三点目标:
更快的遍历速度
对JSON格式来说,太大的JSON结构会导致数据遍历非常慢。在JSON中,要跳过一个文档进行数据读取,需要对此文档进行扫描才行,需要进行麻烦的数据结构匹配,比如括号的匹配,而BSON对JSON的一大改进就是,它会将JSON的每一个元素的长度存在元素的头部,这样你只需要读取到元素长度就能直接seek到指定的点上进行读取了。操作更简易
对JSON来说,数据存储是无类型的,比如你要修改基本一个值,从9到10,由于从一个字符变成了两个,所以可能其后面的所有内容都需要往后移一位才可以。而使用BSON,你可以指定这个列为数字列,那么无论数字从9长到10还是100,我们都只是在存储数字的那一位上进行修改,不会导致数据总长变大。当然,在MongoDB中,如果数字从整形增大到长整型,还是会导致数据总长变大的。增加了额外的数据类型
JSON是一个很方便的数据交换格式,但是其类型比较有限。BSON在其基础上增加了“byte array”数据类型。这使得二进制的存储不再需要先base64转换后再存成JSON。大大减少了计算开销和数据大小。但是,在有的时候, BSON相对JSON来说也并没有空间上的优势,比如对{“field”:7},在JSON的存储上7只使用了一个字节,而如果用BSON,那就是至少4个字节(32位)。目前在10gen的努力下,BSON已经有了针对多种语言的编码解码包。并且都是Apache 2 license下开源的。并且还在随着MongoDB进一步地发展。
参考:https://blog.csdn.net/m0_38110132/article/details/77716792、【MongoDB】BSON类型_chechengtao-CSDN博客
| 数据类型 | 描述 | 举例 |
|---|---|---|
| 字符串 | UTF-8字符串都可表示为字符串类型的数据 | {“x” : “foobar”} |
| 对象id | 对象id是文档的12字节的唯一ID | {“X” :ObjectId() } |
| 布尔值 | 真或者假:true或者false | {“x”:true} |
| 数组 | 值的集合或者列表可以表示成数组 | {“x” : [“a”, “b”, “c”]} |
| 32位整数 | 类型不可用。JavaScript仅支持64位浮点数,所以32位整数会被自动转换。 | shell是不支持该类型的,shell中默认会转换成64位浮点数 |
| 64位整数 | 不支持这个类型。shell会使用一个特殊的内嵌文档来显示64位整数 | shell是不支持该类型的,shell中默认会转换成64位浮点数 |
| 64位浮点数 | shell中的数字就是这一种类型 | {“x”:3.14159,”y”:3} |
| null | 表示空值或者未定义的对象 | {“x”:null} |
| 符号 | shell不支持,shell会将数据库中的符号类型的数据自动转换成字符串 | |
| 正则表达式 | 文档中可以包含正则表达式,采用JavaScript的正则表达式语法 | {“x” : /foobar/i} |
| 代码 | 文档中还可以包含JavaScript代码 | |
| 二进制数据 | 二进制数据可以由任意字节的串组成,不过shell中无法使用 | |
| 最大值/最 小值 | BSON包括一个特殊类型,表示可能的最大值。shell中没有这个类型。 |
P.S. shell默认使用64位浮点型数值。{“x”:3.14} 或 {“x”:3}。对于整型值,可以使用NumberInt(4字节符号整数)或 NumberLong(8字节符号整数),{“x”:NumberInt(“3”)} 或 {“x”:NumberLong(“3”)}
【选读/点击查看】MongoDB中ObjectId的含义和规则是什么?
ObjectId比较小,还是唯一的,可以快速生成并排序。ObjectId值的长度为12个字节,包括:
- 4字节的时间戳(自Unix时代以来以秒为单位的时间戳值),代表ObjectId的创建
- 5字节的随机值
- 3字节的递增计数器,初始化值是随机值
虽然BSON格式本身是低位字节序,但时间戳和计数器值却是高位字节序,最有效字节出现在字节序列前端。
字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。
字节序分为两类:
Big-Endian和Little-Endian,定义如下:
Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。- 网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
在MongoDB中,存储在集合中的每个文档都需要一个唯一的_id字段作为主键。如果插入的文档省略_id字段,则MongoDB驱动程序会自动为_id字段生成ObjectId类型值。
同理,通过upsert:true更新操作插入的文档时,若_id字段省略,也自动生成。
在_id字段中使用ObjectIds具有以下额外优点:
- 通过mongo shell,可以使用
ObjectId.getTimestamp()方法查看ObjectId的创建时间。 - 在存储ObjectId值的_id字段上进行排序大致相当于按创建时间进行排序。
尽管ObjectId值应随时间增加,但不一定是单调的。这是因为他们:
- ObjectId仅包含秒级时间戳,因此在同一秒内创建的ObjectId值没有保证的顺序
- 由客户端生成,客户端可能具有不同的系统时钟。
业务应用场景
传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。
“三高” 需求
High performance:对数据库高并发读写的需求。Huge Storage:对海量数据的高效率存储和访问的需求。High Scalability&&High Availability:对数据库的高可扩展性和高可用性的需求。
具体的应用场景
- 社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
- 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问。
- 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将
- 订单所有的变更读取出来。
- 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
- 视频直播,使用 MongoDB 存储用户信息、点赞互动信息等。
场景共性
- 数据量大
- 写入操作频繁(读写都很频繁)
- 价值较低的数据,对事务性要求不高
对于这样的数据,我们更适合使用MongoDB来实现数据的存储。
什么时候选择 MongoDB
- 应用
不需要事务及复杂join(关联)支持 - 新应用,需求会变,数据模型无法确定,想
快速迭代开发 - 应用需要
2000-3000以上的读写QPS(更高也可以) - 应用需要
TB甚至PB级别数据存储 - 应用发展迅速,需要能
快速水平扩展(不知道是不是指横向扩展?) - 应用要求存储的
数据不丢失 - 应用需要99.999%
高可用 - 应用需要
大量的地理位置查询、文本查询
如果上述有 1 个符合,可以考虑 MongoDB, 2 个及以上的符合,选择 MongoDB 绝不会后悔。
单机部署
Windows安装方式
【选读/点击查看】MongoDB的版本命名规范
MongoDB的版本命名规范如:x.y.z;
y为奇数时表示当前版本为开发版,如:1.5.2、4.1.13;
y为偶数时表示当前版本为稳定版,如:1.6.3、4.0.10;
z是修正版本号,数字越大越好。
详情:http://docs.mongodb.org/manual/release-notes/#release-version-numbers
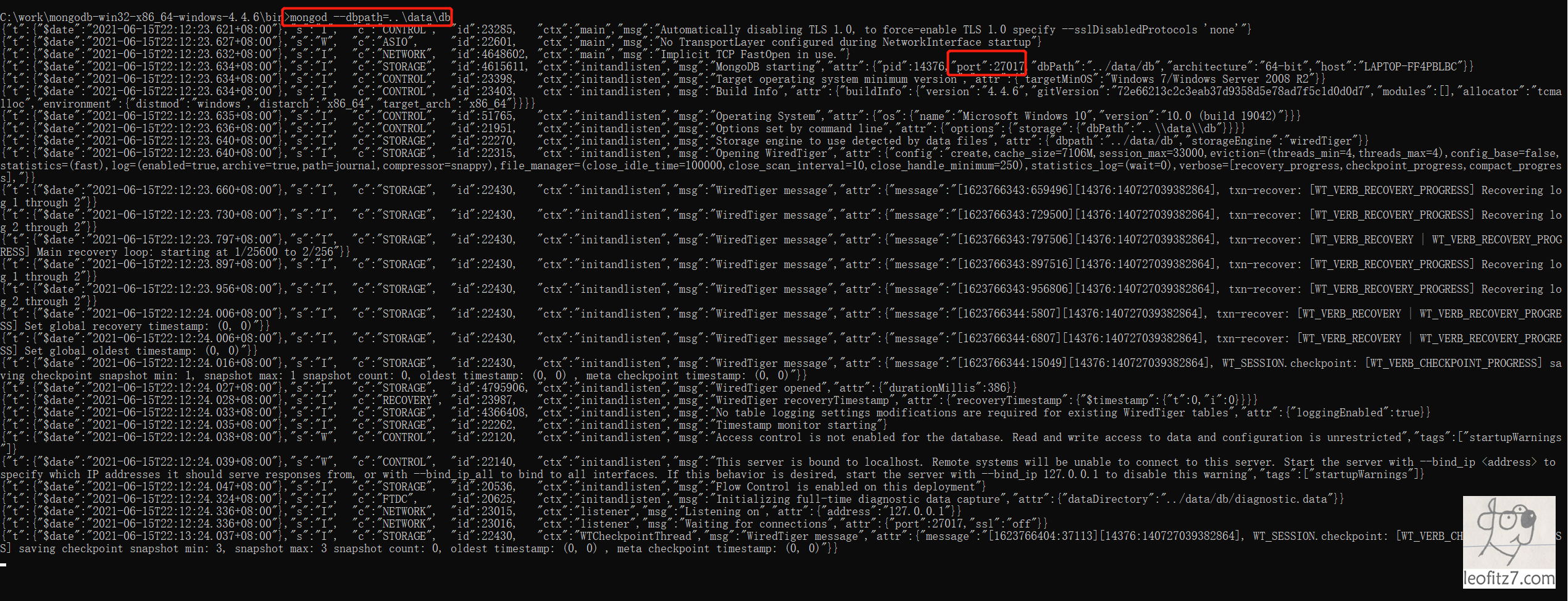
1)命令行参数方式启动服务(调试用)
MongoDB根目录下创建文件夹data/db(data文件夹与bin文件夹同级)bin目录下打开cmd,输入mongod --dbpath=..\data\db --port=27000(不输入--port默认27017)
2)配置文件方式启动服务(部署用)
MongoDB根目录下创建文件夹config(config文件夹与bin文件夹同级)- 创建
mongod.conf文件,内容如下
1 | storage: |
文件内容符合 YAML 语法格式,所以需要注意缩进。dbPath 的内容请自行替换。点击查看官方详细配置说明
P.S. 复制的时候有可能导致缩进问题,如果缩进错误,会报错,所以通常我会手打一遍,或者先复制到 notePad++ 上,再复制到配置文件中,防止这种低级错误的出现。

bin目录下打开cmd,输入mongod -f ../config/mongod.conf或mongod --config ../config/mongod.conf
Shell 启动
启动 Mongo 后,新打开 cmd 输入如下命令:mongo --host=127.0.0.1 --port=27000
Linux安装方式
等买服务器的,虚拟机上先不弄,回来再填这儿的坑。
常用命令
数据库说明
- admin:将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
【选读/点击查看】数据库命名规则
数据库名可以是满足以下条件的任意UTF-8字符串。
不能是空字符串(””)。
不得含有’ ‘(空格)、.、$、/、\和\0 (空字符)。
应全部小写。 最多64字节。
数据库操作
- 创建数据库:
use 数据库名,如果数据库不存在则自动创建(刚创建的集合没有一个文档,因此存在内存中),使用show dbs查不到创建的数据库(因为查的是磁盘) - 权限下查看所有数据库:
show dbsorshow databases - 查看当前正在使用的数据库命令:
db,MongoDB 中默认的数据库为 test,如果你没有选择数据库,集合将存放在 test 数据库中。 - 删除数据库 :
db.dropDatabase(),主要用来删除已经持久化的数据库
集合操作
- 创建集合 :
db.createCollection(name) - 删除集合 :
db.集合名称.drop() - 显示集合 :
show collectionsorshow tables
CRUD
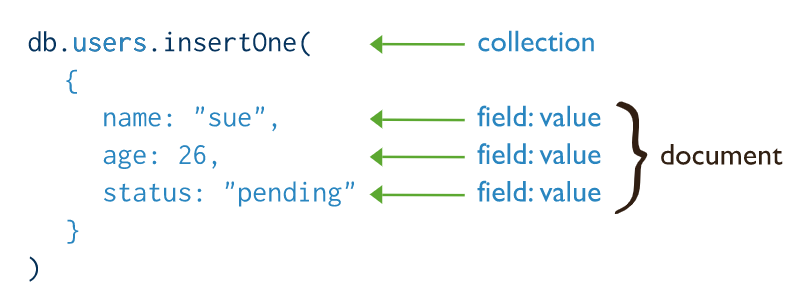
Create
insertOne()
insertMany()
1 | db.collection.insertMany( |
| Parameter | Type | Description |
|---|---|---|
document |
document | An array of documents to insert into the collection. |
writeConcern |
document | Optional. A document expressing the write concern. Omit to use the default write concern.Do not explicitly set the write concern for the operation if run in a transaction. To use write concern with transactions, see Transactions and Write Concern. |
ordered |
boolean | Optional. A boolean specifying whether the mongod instance should perform an ordered or unordered insert. Defaults to true. |
如果
ordered是false,那么插入的文档是无序的,并且可能会为了增强性能,而被mongod排序。如果用unordered的方式insertMany(),就别指望能有序插入QAQ。If
orderedis set to false, documents are inserted in an unordered format and may be reordered bymongodto increase performance. Applications should not depend on ordering of inserts if using an unorderedinsertMany().在一个已经排序的分片集合中使用
insertMant(),ordered比unordered要慢,你必须得等着!!Executing an
orderedlist of operations on a sharded collection will generally be slower than executing anunorderedlist since with an ordered list, each operation must wait for the previous operation to finish.如果一个集合不存在,那么
insertMant()只会在写入成功时,创建这个集合。If the collection does not exist, then
insertMany()creates the collection on successful write.一个文档最大16MB,之所以设置个最大数,是为了不占用过多的RAM( 随机存取器 random access memory),长时间传输,以及过多的带宽消耗,想存储大文档请看
GridFS。The maximum BSON document size is 16 megabytes.
The maximum document size helps ensure that a single document cannot use excessive amount of RAM or, during transmission, excessive amount of bandwidth. To store documents larger than the maximum size, MongoDB provides the GridFS API. See
mongofilesand the documentation for your driver for more information about GridFS.
Retrieve
Update
updateOne()
1 | db.collection.updateOne( |
updateMany()

Update Operators
$currentDate
含义:设定指定字段为当前时间
语法: { $currentDate: { <field1>: <typeSpecification1>, ... } }
示例:
1 | db.test.updateOne( {_id : 1}, |
实战:
1 | // truncate |
$inc
含义:指定字段增加或减少指定数量
语法: { $inc: { <field1>: <amount1>, <field2>: <amount2>, ... } }
示例:
1 | db.test.updateOne({ _id : 1}, |
实战:
1 | // truncate |
$min/$max
含义:仅当某值小于或大于库内的值时才更新该字段。
语法: { $min: { <field1>: <value1>, ... } } or { $max: { <field1>: <value1>, ... } }
示例:
1 | db.test.updateOne({ _id : 1}, |
实战:
1 | // truncate |
P.S.
此字段支持时间的比较,无论库内存的格式是
Date还是ISODate1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// truncate
db.getCollection("test").deleteMany({});
// insert
db.test.insertMany(
[
{
_id: 1,
desc: "crafts",
dateEntered: ISODate("2013-10-01T05:00:00Z"),
dateExpired: ISODate("2013-10-01T16:38:16Z")
}
]
)
// Date
db.tags.update(
{ _id: 1 },
{ $min: { dateEntered: new Date("2013-09-25") } }
)
+---+------------------------+------------------------+------+
|_id|dateEntered |dateExpired |desc |
+---+------------------------+------------------------+------+
|1 |2013-09-25T00:00:00.000Z|2013-10-01T16:38:16.000Z|crafts|
+---+------------------------+------------------------+------+
$mul
含义:库内字段根据某值成倍数变化
语法: { $mul: { <field1>: <number1>, ... } }
示例:
1 | db.test.update( |
实战:
1 | // truncate |
$rename
含义:库内字段根据某值成倍数变化
语法: { $mul: { <field1>: <number1>, ... } }
示例:
1 | db.test.update( |
实战:
1 | // truncate |
P.S. :
如果字段不存在,则什么也不发生。
If the field to rename does not exist in a document,
$renamedoes nothing (i.e. no operation).如果字段嵌入在数组中,则不起作用。
For fields in embedded documents, the
$renameoperator can rename these fields as well as move the fields in and out of embedded documents.$renamedoes not work if these fields are in array elements.
$set
含义:设定文档中字段的值
语法: { $set: { <field1>: <value1>, ... } }
示例:
1 | db.test.update( |
实战:
1 | // truncate |
P.S. :
如果设定的字段不存在,则会添加这个字段,支持内嵌设定。
If the field does not exist,
$setwill add a new field with the specified value, provided that the new field does not violate a type constraint. If you specify a dotted path for a non-existent field,$setwill create the embedded documents as needed to fulfill the dotted path to the field.
Delete
deleteOne()
1 | db.collection.deleteOne( |
例如:
1 | db.orders.deleteOne( { "expiryts" : { $lt: ISODate("2015-11-01T12:40:15Z") } } ); |
想精确的删除最好用唯一索引,例如
_id。db.collection.deleteOne()deletes the first document that matches the filter. Use a field that is part of a unique index such as_idfor precise deletions.
deleteMany()
1 | db.collection.deleteMany( |
对于指定大小的集合(Capped Collection )而言,不能使用
deleteMany(),如果想删除整个集合,用db.collection.drop()代替。db.collection.deleteMany()throws aWriteErrorexception if used on a capped collection. To remove all documents from a capped collection, usedb.collection.drop().
原因:Capped Collection 是一种特殊的集合,它大小固定,当集合的大小达到指定大小时,新数据覆盖老数据。Capped collections可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新Capped collections中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。(FROM :https://blog.csdn.net/welcome66/article/details/84693068)
适用场景:日志文件、最近通话记录、最近联系人、最近聊天记录等。
特点:
写入速度提升。固定集合中的数据被顺序的写入磁盘上的固定空间。所以,不会因为其他集合的一些随机性的写操作而”中断”,因而其写入速度更快(不建索引,性能更好)。
无需额外删除旧文档。固定集合会自动覆盖掉最老的文档,因而不需要在额外的工作进行旧文档删除。设置Job进行旧文档的定时删除容易形成性能的压力毛刺。(压力毛刺:https://www.jianshu.com/p/7249c488e5d7)
创建:
db.createCollection("collectionsName",{capped:true,size:1073741824,max:50})每个文件最大为1G,保留最多50个对象。查看是否为固定集合:
db.collectionsName.isCapped()->true删除时使用索引:
hint:{索引字段:1}(暂不清楚1的含义,等到索引篇再处理此处)1
2
3
4db.members.deleteMany(
{ "points": { $lte: 20 }, "status": "P" },
{ hint: { status: 1 } }
)如果索引不存在,则会报错
P.S. :
创建固定集合时想指定文档个数
max,必须指定集合大小size,假设文档个数没到限制,但集合大小达到限制了,同样会删除旧文档。Optional. The maximum number of documents allowed in the capped collection. The
sizelimit takes precedence over this limit. If a capped collection reaches thesizelimit before it reaches the maximum number of documents, MongoDB removes old documents. If you prefer to use themaxlimit, ensure that thesizelimit, which is required for a capped collection, is sufficient to contain the maximum number of documents.固定集合的
size小于等于4096个字节的,则集合大小的上限为4096,如果大于,则是256倍数个字节大小。If the
sizefield is less than or equal to 4096, then the collection will have a cap of 4096 bytes. Otherwise, MongoDB will raise the provided size to make it an integer multiple of 256.如果不加排序,固定集合的查询结果
find()一定是顺序写入的排序方式,如果想倒序输出,db.cappedCollection.find().sort( { $natural: -1 } )普通集合可以使用
convertToCapped转换为固定集合,但是固定集合不能转换为普通集合;且转换后索引丢失,需要重新手动创建。如果转换固定集合的大小size小于普通集合,则在磁盘中以FIFO排序覆盖文档。The
convertToCappedwill not recreate indexes from the original collection on the new collection, other than the index on the_idfield. If you need indexes on this collection you will need to create these indexes after the conversion is complete.If the
capped sizespecified for the capped collection is smaller than the size of the original uncapped collection, then MongoDB will overwrite documents in the capped collection based on insertion order, or first in, first out order.普通集合转换为固定集合时,会为此操作上一个锁,任何对此集合的锁操作都会阻塞,直到转换操作完成。
This holds a database exclusive lock for the duration of the operation. Other operations which lock the same database will be blocked until the operation completes. See What locks are taken by some common client operations? for operations that lock the database.
 微信
微信- 支付宝




